




Большие языковые модели умеют многое: генерировать текст, писать код, резюмировать документы. Но для прикладных задач этого мало: универсальная модель не знает контекста компании, не учитывает отраслевую специфику и ошибается там, где цена ошибки высока.
В службе поддержки важно, чтобы бот отвечал по актуальной базе знаний, а в юридическом департаменте — чтобы формулировки были точными и соответствовали внутренним регламентам. Без настройки LLM с этим не справится.
Разберемся, как компании адаптируют модели под себя: какие есть подходы, этапы, инструменты и какие ошибки можно заранее исключить.
Что такое настройка LLM и почему она важна?
Большие языковые модели создаются на обширных наборах данных — это миллиарды слов из открытых источников, где все перемешано: статьи, коды, диалоги, инструкции. Это дает мощную языковую базу, но не делает модель подходящей для реальных задач конкретного продукта или бренда.
Настройка LLM — это адаптация готовой модели под задачи компании. Настройка модели не означает ее обучение с нуля. Полное переобучение LLM требует десятков тысяч GPU-часов и терабайты данных — это задача для крупных лабораторий. На практике используется дообучение: модель сохраняет общий «языковой интеллект», но получает дополнительный опыт на ваших собственных данных.
Например, компания внедряет чат-бота, который отвечает на вопросы по внутренним регламентам. Без настройки модель отвечает уверенно, но может выдавать устаревшие правила и общие ответы.
После настройки модель дает ссылки на актуальные документы, использует правильные формулировки и знает конкретный контекст.
Зачем это нужно:
в прикладных задачах требуется точность и предсказуемость ответов, особенно в праве, медицине и финансах;
универсальная модель обобщает знания в узких темах — без настройки растет число ошибок в терминах и фактах.
Дообученная модель может научиться:
отвечать в стиле вашей техподдержки;
использовать терминологию конкретного департамента;
учитывать юридические ограничения при генерации контрактов.
Например, клиент спрашивает у чат-бота о возврате товара.
До настройки (модель без контекста):
«Вы можете вернуть товар в течение 14 дней согласно закону о защите прав потребителей».
После настройки на внутренних данных магазина и конкретного сайта:
«Вы можете вернуть товар в течение 14 дней с момента получения заказа. Для этого перейдите в личный кабинет, выберите заказ и нажмите “Запросить возврат”. Подробности — в разделе “Гарантии и возврат”».
В первом случае модель говорит общими фразами. Во втором — дает точную инструкцию благодаря кастомизации больших языковых моделей.
Типы настройки больших языковых моделей
Адаптация LLM — это не универсальный процесс. Существуют разные подходы, их выбор зависит от задач, объема данных, инфраструктуры и требований к точности. Ниже — основные методы настройки, которые применяются на практике.
Промпт-инжиниринг
Самый доступный способ влиять на поведение модели. Он не требует изменения самой архитектуры — только корректной формулировки запроса. По сути, вы обучаете модель не «знаниям», а контексту, в котором она должна работать.
Например:
Запрос «Как установить Python?» дает базовый ответ, общий и поверхностный.
Но если задать:
«Ты — технический специалист службы поддержки. Пользователь — начинающий, у него Windows 11 и нет админ-доступа. Опиши пошагово, как установить Python через установщик без прав администратора. Укажи, какие галочки поставить в мастере установки и как проверить, что все работает. Ответ должен быть понятным и без лишней терминологии».
В таком случае результат будет точнее: модель учтет систему, уровень пользователя, ограничения и нужную структуру ответа.
Подходит для:
MVP и быстрых прототипов;
задач с узким спектром сценариев;
случаев, когда дообучение недоступно.
Ограничения:
модель не усваивает специфические данные;
нестабильность при сложных диалогах;
низкий уровень персонализации.
Тонкая настройка LLM (fine-tuning)
Это полноценное дообучение модели на целевых данных. Модель сохраняет языковую основу, но подстраивается под терминологию, формат и структуру ваших задач. Это может быть переписка с клиентами, юридические документы, инструкции — любые тексты, которые отражают «язык» бизнеса.
Подходит для:
автоматизации процессов, где важна точность;
задач с высоким риском ошибки (медицина, право);
внедрения LLM в продакшн-продукты.
Ограничения:
требует ресурсоемкой подготовки;
возможны сложности с инфраструктурой;
модель нуждается в регулярном переобучении по мере накопления данных.
Дообучение через адаптеры
Это облегченная альтернатива fine-tuning. Модель остается неизменной, но к ней подключаются специальные модули (адаптеры), которые «настраиваются» под задачу. Метод позволяет быстро переключаться между сценариями и использовать одну модель в разных продуктах.
Плюсы:
экономия ресурсов;
масштабируемость;
быстрое внедрение.
Минусы:
возможная потеря точности;
требуется техническая поддержка и понимание архитектуры.
RAG — генерация с доступом к внешним источникам
Retrieval-Augmented Generation — подход, в котором модель не хранит все знания внутри, а запрашивает нужную информацию извне. Это работает, как умная связка: LLM задает вопрос, получает релевантный ответ из базы знаний и использует его для генерации и оптимизации.
Например, юридический отдел крупной компании внедрил бота, который помогает с поиском нормативных актов. Вместо того чтобы дообучать модель на совокупности нормативных правовых актов, настроили RAG. Теперь бот запрашивает нужные статьи из базы и генерирует ответ с учетом актуальных формулировок.
Преимущества:
высокая точность без переобучения;
возможность быстрой актуализации данных;
контроль над источниками знаний.
Ограничения:
зависит от качества базы;
требует собственной системы поиска и хранения;
больше инженерной работы.
Этапы настройки LLM под конкретную задачу
Обучение LLM под задачу — это набор подготовительных, аналитических и инженерных шагов. Ниже — последовательность действий для адаптации модели под конкретную бизнес-задачу.
1) Формулирование задачи
Определяют, какую проблему должна решать модель и по каким признакам поймут, что решение работает. Фиксируют цель, пользователей и канал общения, формат задачи (ответ на вопрос, поиск документа, генерация по шаблону). Сразу задают границы: где ошибки недопустимы, какие темы и источники запрещены.
2) Сбор и подготовка данных для LLM
Собирают внутренние материалы: диалоги поддержки, регламенты, FAQ, шаблоны писем. Убирают дубли и устаревшие версии, анонимизируют персональные данные, при необходимости размечают пары «вопрос → корректный ответ» и желаемый тон. Делят корпус на части для обучения, проверки в процессе и финального теста — так видно реальный прогресс, а не «зазубривание».
3) Выбор подхода к адаптации
Смотрят на цель и ресурсы. Если правила часто меняются и важны ссылки на документы, используют RAG — модель берет факты из вашей базы знаний и вставляет их в ответ. Если критичны стиль и терминология, применяют дообучение: модель учат на корпоративных примерах. Легкий вариант — LoRA (обучается небольшая надстройка, а не вся модель). Если сценарий узкий или нужен быстрый прототип, достаточно промпт-инжиниринга — поведение задают формулировкой запроса и шаблоном ответа. Если одна и та же модель нужна в нескольких продуктах, подключают адаптеры — сменные модули под разные роли без полного переобучения.
4) Подготовка инфраструктуры
Определяют, где запускать обучение и работу модели, — в облаке или на своих серверах. Настраивают хранилище для данных и «снимков» модели, учет экспериментов и версий датасетов, доступы и маскирование чувствительных полей. Если используется RAG, строят индекс базы знаний и настраивают поиск по нему, чтобы ответы опирались на свежие и точные фрагменты.
5) Настройка и обучение модели
Приводят модель к нужному поведению. Для дообучения подбирают параметры и запускают несколько итераций с проверкой качества на отложенной выборке. Для RAG настраивают разбиение документов на фрагменты, отбор релевантных кусочков и вставку их в контекст ответа. Для промптов уточняют роли, формат и ограничения. Итог — вариант модели и/или рабочий шаблон, который стабильно дает нужный результат на проверках.
6) Тестирование и оценка качества
Перед запуском модель прогоняют по типичным и «угловым» ситуациям: неполные запросы, конфликтующие данные, провокационные формулировки. Сверяют ответы с эталонными и мнением экспертов.
Оценивают не только точность, но и скорость: за сколько секунд большинство пользователей видит первое слово ответа и за сколько приходит полный текст. Для RAG проверяют наличие ссылок на документы и то, что они действительно по делу. По результатам правят слабые места и повторяют проверку применения LLM в бизнесе.
7) Запуск и сопровождение в продакшне
Встраивают модель в продукт: настраивают сервис, который принимает запросы и возвращает ответы, задают лимиты на длину и стоимость, включают логи и панель показателей. Собирают обратную связь («помогло/не помогло», метки ошибок) и планируют обновления. При изменении правил или падении качества дообучают модель, пересобирают индекс базы знаний и выкатывают обновление без простоя.
Инструменты и инфраструктура для настройки LLM
Чтобы проект с LLM работал стабильно и масштабируемо, важно не только правильно выбрать подход к адаптации, но и выстроить техническую среду вокруг: от моделей и фреймворков до хранилищ и трекинга экспериментов.
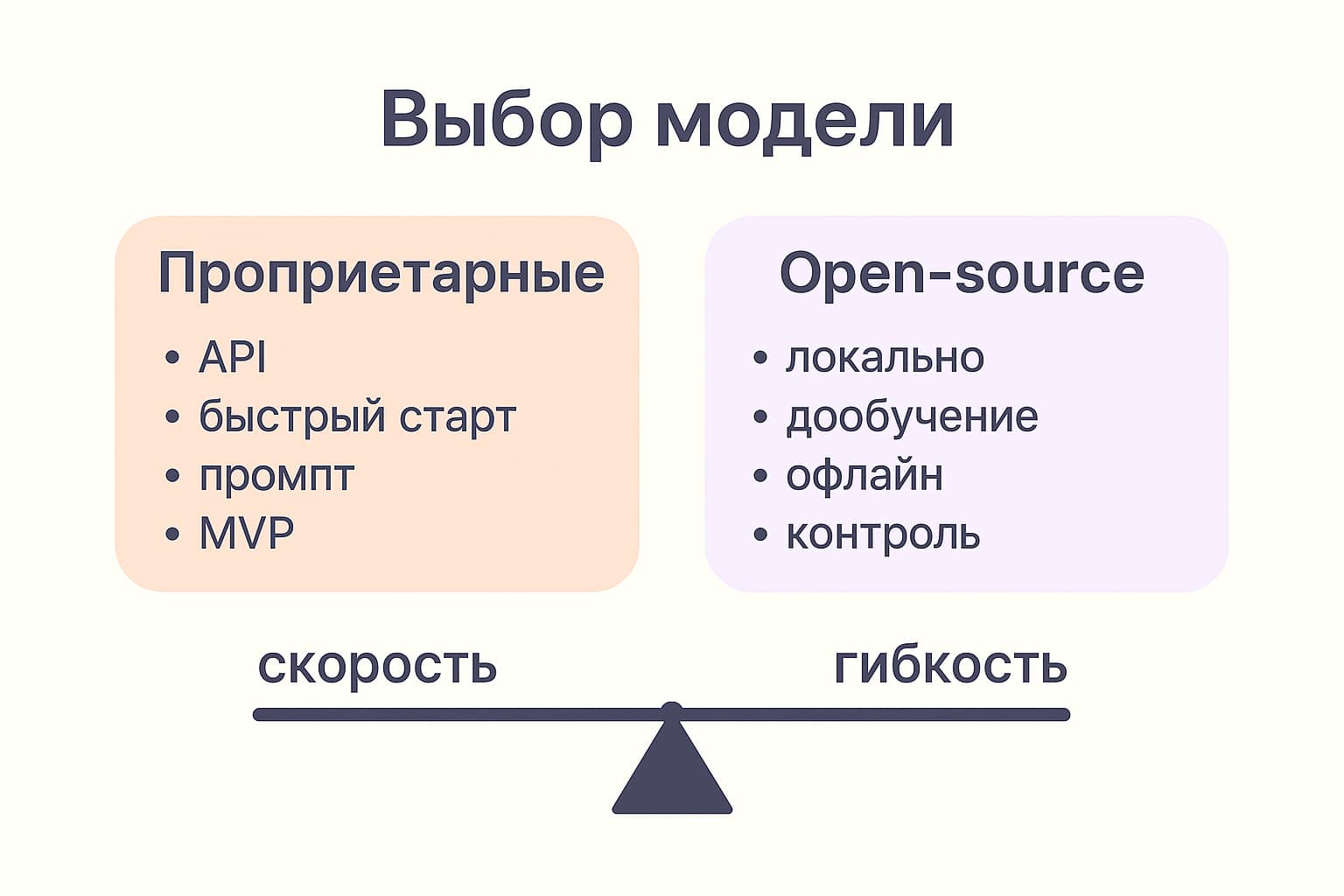
Модели: проприетарные vs open-source
Выбор модели — это выбор баланса между гибкостью, безопасностью и скоростью внедрения.
Проприетарные модели (ChatGPT, Gemini, Claude и др.) — доступны через API. Их нельзя дообучить напрямую, но они удобны для промпт-инжиниринга и быстрых прототипов. Подходят, если данные не критичны и важна скорость запуска.
Open-source модели (LLaMA, Mistral, Falcon, Phi и др.) — можно размещать локально, дообучать и использовать в офлайн-среде. Предпочтительный вариант, если требуется контроль над данными и поведение модели нужно менять под себя.
Выбор зависит от чувствительности данных, требований к кастомизации и возможности поддерживать инфраструктуру.
Технический стек: что нужно для настройки
В зависимости от подхода к адаптации (дообучение, RAG, промпт-инжиниринг) понадобится разный набор инструментов.
Для работы с моделью:
Transformers и PEFT от Hugging Face — для обучения и адаптеров;
LoRA, QLoRA — для легкого дообучения;
PyTorch, DeepSpeed, Accelerate — для ускоренного обучения.Для RAG-систем:
LlamaIndex, LangChain — позволяют подключить документы и базы знаний, обеспечить поиск с генерацией;
FAISS, Weaviate, Qdrant — векторные базы, где модель ищет фрагменты перед ответом.Для трекинга и воспроизводимости:
Weights & Biases, MLflow — фиксируют параметры обучения, метрики, версии моделей;
DVC, Git LFS — для контроля над датасетами и их изменениями.
Каждый из этих инструментов позволяет зафиксировать и повторить нужную конфигурацию — это важно при итерациях и обновлениях модели.
Где все это запускается: инфраструктура для обучения AI
Инфраструктурное решение выбирается в зависимости от задач, объема обучения и политики по данным:
Облако (AWS, GCP, Azure) — удобно для быстрого старта, тестов, краткосрочных задач. Масштабируется и не требует инвестиций в железо.
Собственные серверы с GPU — нужны, если модель постоянно используется или данные не могут покидать периметр. Окупается при длительных проектах.
API-доступ к LLM как услуге (OpenAI, Mistral, Cohere) — можно не разворачивать свою модель, но кастомизация ограничена.
Важно заранее учесть, где будет происходить дообучение языковых моделей, где хранить данные и как обеспечивать откат/перезапуск при ошибках.
Работа с данными: хранение и документация
Данные — основной актив проекта. Инструменты помогают не просто хранить, а отслеживать изменения и обеспечивать прозрачность:
Объектные хранилища (S3, MinIO) — для хранения больших массивов текстов, обучающих выборок, индексов.
Системы контроля данных (DVC, Git LFS) — как Git для датасетов: можно откатить, сравнить, синхронизировать версии.
Документация (Notion, Confluence, Obsidian) — для хранения структуры проекта, описания сценариев, выводов по экспериментам.
Без этих компонентов даже самая хорошо обученная модель быстро теряет актуальность или становится нечитаемой для команды.
Практические советы и ошибки, которых стоит избегать при настройке LLM
Даже мощная модель не даст результата, если неправильно поставить задачу или работать с некачественными данными. Вот типовые ошибки, с которыми часто сталкиваются на практике.
1. Размытая постановка задачи
Попытка «сделать умного помощника» без ясного сценария обычно проваливается. Модель не поймет, что именно от нее требуется: искать информацию, классифицировать сообщения или генерировать ответы. Лучше начать с узкой задачи — например, автоматической генерации отчетов или поддержки пользователей в чате — и расширяться после первых успехов.
2. Недостаток определенных данных
Если в обучающем корпусе случайные документы, а не реальные обращения и ответы, модель будет работать в отрыве от контекста. Особенно это критично в тематиках с терминологией — медицина, финансы, юриспруденция. Лучше меньше данных, но из надежных источников и с ручной валидацией.
3. Отсутствие валидации и переобучение
Когда модель слишком точно запоминает примеры, она теряет гибкость. На новых запросах результат может сильно проседать. Поэтому важно не только обучать, но и проверять: выделять тестовую выборку, следить за метриками и включать проверки на «здравый смысл».
4. Игнорирование обратной связи
Даже хорошо обученная модель быстро устаревает, если не учитывать, как с ней работают пользователи. Без сбора ошибок и фидбэка со временем растет количество промахов. Регулярная итерация — обязательная часть процесса.
5. Слишком сложная архитектура на старте
Иногда хочется сразу внедрить тонкую настройку, кастомный RAG, собственный индекс и плагины. Но сложные системы не прощают ошибок и требуют много ресурсов. Рациональный подход — сначала проверить гипотезу на минимальной версии и только после масштабировать решение.
Примеры успешной настройки LLM для бизнес-задач
Когда модель понимает терминологию, знает процессы и обучена на релевантных данных — она становится полноценным участником бизнес-процесса. Ниже — примеры того, как компании решают реальные задачи с помощью кастомизированных LLM.
Юридический департамент: автоматизация договорного документооборота
Юристы дистрибуционной компании ежедневно правили типовые договоры вручную — вносили повторяющиеся корректировки, проверяли формулировки, искали нужные пункты. Это отнимало 4–5 часов на один документ и не избавляло от риска мелких ошибок.
Решение:
Модель дообучили на 500+ согласованных договорах, шаблонах и юридической переписке. Она научилась:
определять структуру документа;
заполнять ключевые блоки (сроки, ответственность, оплата);
подбирать формулировки в нужном тоне.
Результат:
Время подготовки сократилось до 1–2 часов (экономия 60–70%).
Ушли типичные ошибки: забытые пункты, опечатки, дубли.
Юристы получают черновик, который остается проверить по чек-листу, — вместо сборки с нуля.
Поддержка клиентов в e-commerce: масштабируемый чат-бот
Во время распродаж онлайн-магазин фиксировал трехкратный рост обращений. 80% вопросов были однотипными: статус заказа, возврат товара, условия скидок. Поддержка не справлялась с нагрузкой, а масштабирование команды — дорого и неоперативно.
Решение:
На основе анализа типовых обращений и FAQ выделили основные сценарии взаимодействия. Под каждый — настроили промпты, уточняющие стиль, структуру и источники ответа. Для доступа к актуальной информации модель дополнили мини-RAG, обращающимся к внутренней базе по возвратам и доставке.
Результат:
70% обращений обрабатывались автоматически.
Среднее время ответа сократилось с 180 до 30 секунд.
Качество общения осталось на уровне live-операторов.
Система выдержала пик без найма дополнительных сотрудников.
HR-процессы: фильтрация резюме и подбор кандидатов
HR-агентство получало сотни резюме в день. Рекрутеры вручную читали профили, искали релевантный опыт и составляли краткие выводы. Это занимало до 6 часов в день на одного специалиста.
Решение:
Open-source LLM дообучили на реальных кейсах — старых вакансиях, резюме, переписке и решениях по кандидатам.
Модель научилась:
сравнивать их с требованиями вакансий,
давать обоснование для «подходит/не подходит».
Результат:
Скорость обработки — до 500 резюме в день.
Освобождение 2–3 часа ежедневной загрузки на каждого рекрутера.
Рост релевантных приглашений на интервью на 30%.
Срок от отклика до оффера сократился с 14 до 9 дней.
Заключение
Работа с языковыми моделями требует широкого спектра знаний: от понимания архитектуры и обучения нейросетей до уверенного владения инструментами для подготовки данных, настройки моделей и оценки качества их работы.
Если вы хотите углубить знания, разобраться в современных подходах к работе с данными и развивать компетенции в области ИИ, стоит начать с фундаментальных направлений. В онлайн-школе ProductStar вы найдете программы, которые помогут сформировать прочную базу и начать применять навыки в реальных задачах.







