




Датасеты — важная часть современного цифрового мира. Без них не получится строить модели прогнозирования, извлекать инсайты из массивов информации или обучать нейросети.
В новом материале расскажем, что такое датасет, какие бывают виды данных, какая у них структура, а также как подготовить и использовать датасеты для анализа данных и машинного обучения.
Что такое датасет
Датасет (от англ. dataset) — это набор собранных и упорядоченных данных, предназначенных для хранения, обработки и анализа. В него может входить числовая, текстовая, графическая или смешанная информация.
Чаще всего датасеты выглядят как таблицы со строками и столбцами. В строках содержится информация об объектах наблюдения, например, пользователи, транзакции, товары. А в столбцах — их характеристики: возраст, дата покупки и др.
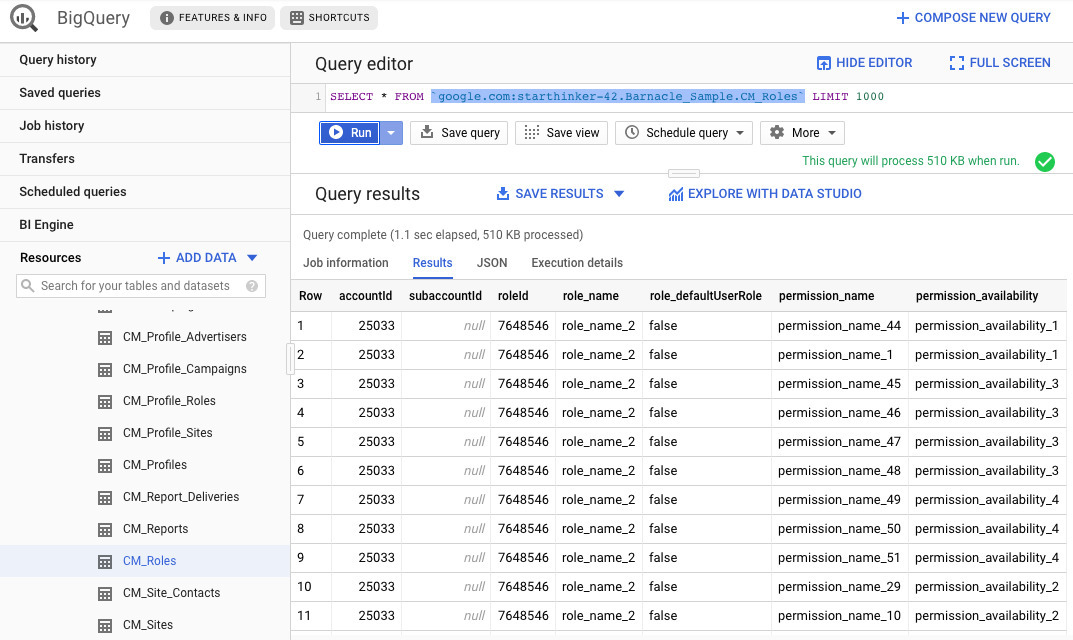
Пример SQL-запроса к датасету в Google BigQuery: анализ таблицы пользовательских ролей и прав доступа
На примере выше показан датасет с пользовательскими ролями и разрешениями в системе управления рекламными кампаниями. Каждая строка содержит связку «аккаунт — роль — разрешение», а столбцы описывают параметры доступа для каждого аккаунта.
Для чего нужны датасеты и где они используются
Датасеты применяются в разных областях — от науки и госструктур до маркетинга и финтеха. Их используют как для исследовательских задач, так и в повседневной аналитике.
Датасет — это основа для решений, которые позволяют автоматизировать процессы, создавать конкурентные преимущества и повышать эффективность продуктов и сервисов. Ниже перечислены самые популярные сферы, где активно используются наборы данных.
Искусственный интеллект и машинное обучение. Качественные и полные датасеты необходимы для точного обучения моделей, а также решения задач классификации, регрессии, кластеризации и других типов.
Бизнес-аналитика. Датасеты помогают выявить закономерности в маркетинговых стратегиях, продажах и поведении покупателей.
Научные исследования. В биологии, социологии, психологии, экономике исследователи используют наборы данных для верификации гипотез.
Государственные данные. Правительства публикуют датасеты с демографическими, экологическими, социальными и экономическими показателями.
Разработка сервисов и приложений. Программисты используют датасеты для построения чат-ботов, голосовых помощников, рекомендательных систем и других сервисов.
Виды датасетов
Прежде чем начать работу с датасетами, важно разобраться в их разновидностях. Это поможет выбрать подходящий набор данных под конкретную задачу — будь то машинное обучение, бизнес-аналитика или визуализация.
Датасеты можно классифицировать по типу данных, цели использования, доступности или способу получения информации.
По типы данных выделяют следующие датасеты:
табличные датасеты — CSV, Excel;
текстовые — JSON, XML, txt;
изображения — JPEG, PNG, BMP;
аудио — WAV, MP3;
видео — MP4, AVI.
По цели использования:
обучающие датасеты (training set) — для обучения моделей;
проверочные (validation set) — для настройки параметров и выбора модели;
тестовые (test set) — для оценки качества модели на новых данных.
По доступности:
открытые датасеты — Kaggle, OpenML, Google Dataset Search;
закрытые — внутренние базы компаний, защищенные NDA.
По источнику сбора:
сгенерированные вручную;
собранные автоматически — с помощью скриптов или парсинга;
полученные от третьих лиц — партнеров или поставщиков.
Структура датасета
Чтобы эффективно работать с датасетами, нужно понимать их структуру. Особенно это важно при использовании табличных данных — от их корректности напрямую зависит качество анализа, обучение моделей и визуализация.
Рассмотрим основные компоненты, из которых формируется датасет, особенно в табличной форме:
Заголовки — содержат названия признаков (столбцов), которые описывают характеристики объектов.
Наблюдения — строки таблицы, содержащие значения признаков для конкретного объекта.
Типы данных — числовые, категориальные, текстовые, временные метки и другие компоненты.
Пропущенные значения — пустые ячейки, которые требует особой обработки.
Метаданные — это описание структуры, источников, условий сбора и прочие сопроводительные данные.
Критерии выбора и подготовки датасета
От выбора правильного датасета зависит успех всего проекта. Обучаете ли вы модель, готовите отчет или работаете с аналитикой — именно от качества и релевантности данных зависят будущие результаты.
Перечислим основные критерии, которым должен соответствовать хороший датасет.
Релевантность. Данные должны соответствовать поставленной цели анализа.
Например, чтобы спрогнозировать спрос на товар, нужно использовать данные о продажах. Если использовать датасеты о поведении пользователей в соцсети, нерелевантные данные могут ввести модель в заблуждение и понизить точность результатов.
Полнота. Чем меньше пропущенных значений, тем достовернее анализ — в иных случаях, отсутствие данных в ключевых столбцах приведет к искаженным итогам.
Качество. У данных «на входе» должно быть хорошее качество. Это значит, что в датасетах нужно исключить противоречивую информацию, дубликаты и ошибки.
Чтобы качественно собирать данные для датасетов, рекомендуем пройти курс от онлайн-школы ProductStar «Профессия Data Scientist». За 250 академических часов, 128 онлайн-уроков вы с нуля станете специалистом по работе с BigData и гарантированно найдете работу. И все это с поддержкой экспертов в области.
Объем. Датасеты для анализа данных должны охватывать большое количество наблюдений, чтобы результат был статистически значимым. Это особенно важно при построении моделей машинного обучения — маленький объем данных может привести к неспособности обобщать и переобучению.
Актуальность. Данные нужно постоянно обновлять, потому что рыночные условия, бизнес-модели и поведение пользователей постоянно меняются. А использование устаревших датасетов может привести к неэффективным решениям и ошибочным выводам.
Баланс классов. Важно, чтобы классы были представлены сбалансированно. В случае дисбаланса алгоритм может начать игнорировать меньший класс — тогда придется применять методы балансировки. Например, oversampling, undersampling или генерация синтетических данных SMOTE.
Как создать и подготовить датасет
Создание датасета — длительный процесс, от которого зависит успешность анализа и дальнейших выводов. При работе с данными нужен внимательный подход, понимание конечной цели и точность. Рассмотрим основные стадии подготовки набора данных и создания датасетов.
Постановка цели — перед началом работы нужно определиться, зачем собираются данные, какие параметры учитывать, какие метрики будут ключевыми и как их структурировать.
Пример. Для прогнозирования продаж важно собирать не только данные о транзакциях, но и информацию о сезонности, рекламных кампаниях и внешних факторах.
Источники датасетов — источниками могут стать как внешние API-сервисы, веб-скрапинг, опросы, так и внутренние CRM, BI-системы и другие ресурсы. На этом этапе важно оценить надежность источников, юридическую чистоту информации и техническую возможность интеграции.
Сбор данных — в зависимости от проекта сбор информации может быть автоматизированным, например, через Python-библиотеки. Также есть варианты с ручным сбором сведений через анкетирование и с полуавтоматическим сбором данных с помощью экспорта из Excel или Google Sheets.
Очистка — это один из критически важных этапов, на котором нужно очистить датасет, не потеряв значимые данные. Для этого применяются фильтрации, проверка диапазонов и соответствий, удаление и коррекция ошибок.
Преобразование — после чистки данных нужно привести таблицу к нужному формату: числовому, категориальному, one-hot encoding и т. д. Именно на этом этапе создаются производные признаки: день недели или разница между заказами.
Анализ — прежде чем приступить к подготовке отчетов и построению моделей, нужно провести разведочный анализ данных. С его помощью можно выявить повторные выбросы, сформулировать гипотезы на будущее и найти нелогичные корреляции.
Примеры использования датасетов
Рекомендательные системы с алгоритмами. Компании используют пользовательские датасеты для персонализации контента — в них содержатся истории просмотров, клики и оценки. Модели машинного обучения анализируют эти данные и формируют индивидуальные предложения.
Финансы, банки, финтех-компании. В сфере финансов применяют транзакционные датасеты, чтобы строить скоринговые модели, прогнозировать платежеспособность клиентов и выявить подозрительные операции.
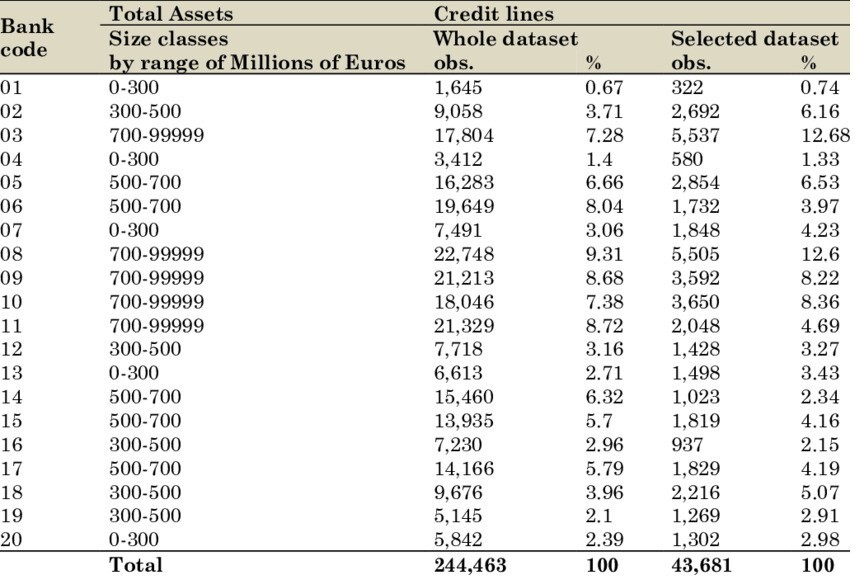
Сводная таблица по банкам: активы, кредитные линии и выборка по датасету.
Медицинские исследования. Еще одна область, где используются датасеты — медицина. Набор данных с историями болезней, снимками МРТ, КТ, результатами анализов позволяют врачам прогнозировать течение заболеваний, находить связь между диагнозами и симптомами, корректировать методы лечения.
Городской транспорт. Власти города используют датасеты с IoT-датчиков, камер и систем оплаты, чтобы анализировать трафик, прогнозировать пробки и проектировать более эффективные маршруты общественного транспорта.
EdTech и образование. Образовательные платформы проводят анализ поведения учащихся — просмотренные курсы, частота входа и успешность выполнения заданий. Все это поможет адаптировать программы под каждого студента и минимизировать риски исключения с курса.
Лучшие датасеты
Iris Dataset — это классическая модель для обучения базовым алгоритмам и визуализации.
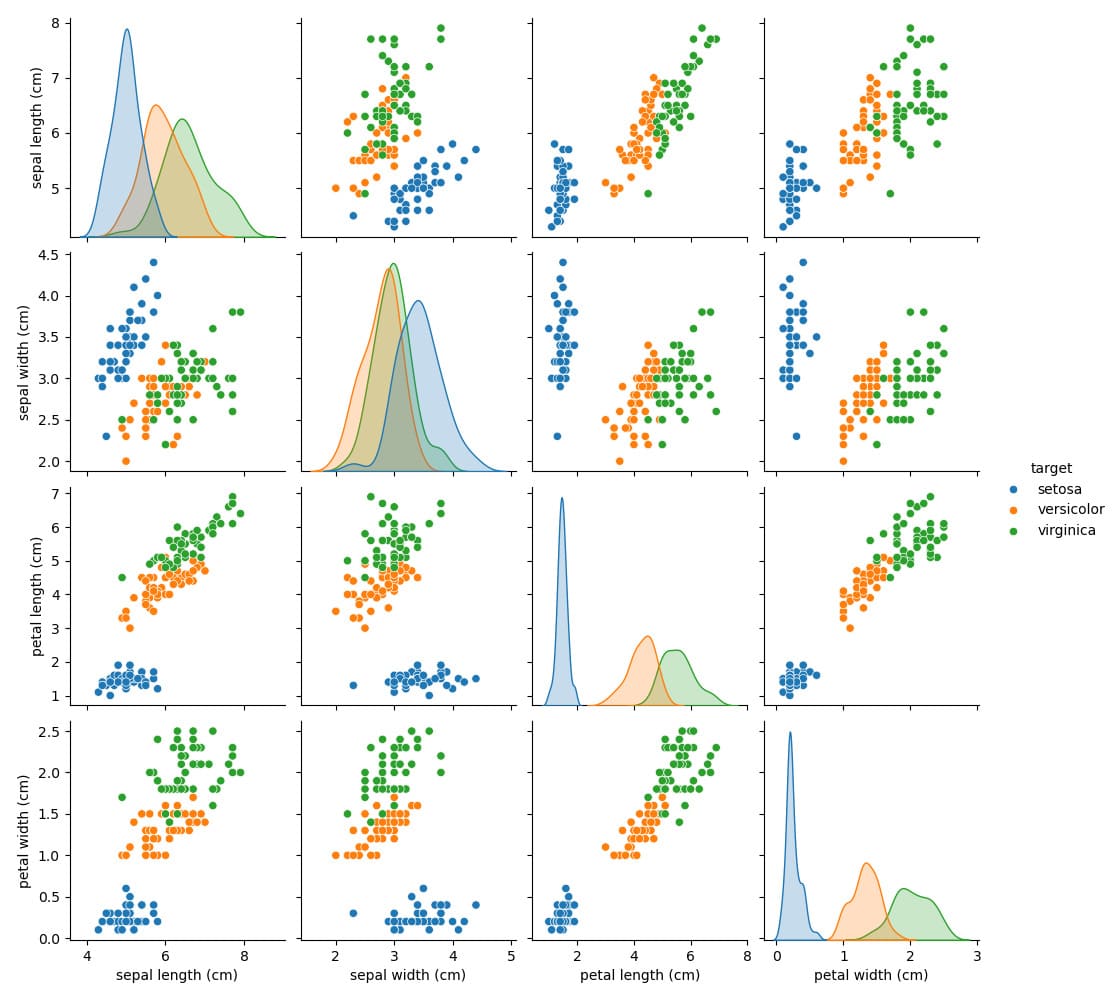
Визуализация датасета Iris: распределения и взаимосвязи признаков по видам ирисов.
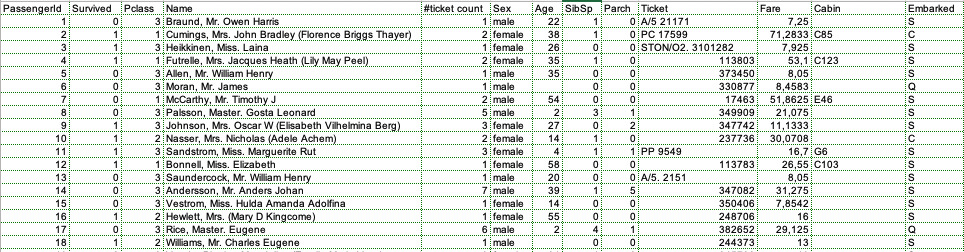
Таблица с данными пассажиров Titanic: выживание, пол, возраст и билетные параметры.
Google BigQuery Public Datasets — это коллекция обширных данных от Google для SQL-анализа и обучения.
Коротко о главном
Датасет представляет собой структурированный набор данных для хранения, обработки и анализа информации, который используется в науке, государственных структурах, искусственном интеллекте, бизнесе, при разработке сервисов и приложений.
Основной вид данных — это таблицы, изображения, тексты, видео и аудио. По назначению выделяют обучающие, проверочные и тестовые датасеты, а по доступности — открытые и закрытые.
Структура датасета включает в себя заголовки, строки, столбцы, типы данных, метаданные и пропуски. Этапы создания датасетов — определение цели, выбор источников, сбор, очистка, преобразование и анализ данных.
Популярные датасеты — это Iris, MNIST, COCO, IMDB Reviews, OpenStreetMap, Titanic и Google BigQuery Public Datasets.







