




Обмениваются сообщениями не только люди, но и компоненты в сложных IT-системах. Чтобы контролировать это «общение», нужен помощник — именно им и выступает Apache Kafka. Сегодня поговорим о том, для чего нужна эта платформа и как она устроена.
Что такое Apache Kafka
Apache Kafka — распределенная система, задача которой — обрабатывать поступающую в систему информацию в режиме реального времени. Если провести аналогию, то можно сопоставить платформу с мессенджером: в одну систему поступают разные сообщения от контактов, а другие «пользователи» — получают эти письма. Apache Kafka также называют брокером, так как он становится посредником между этими сообщениями.
Систему разработала в 2011 году компания LinkedIn для внутреннего пользования, но позже платформа стала популярной и вышла на широкий рынок. Сегодня ее используют такие компании, как Microsoft, Netflix, The New York Times и другие.

Для чего нужна Apache Kafka
Обработка данных в реальном времени
Kafka позволяет обрабатывать данные сразу же, как только они поступают, а не пачками раз в несколько часов или дней. Это критично для приложений, где важна каждая секунда. Например: системы мошенничества в банковских операциях, мониторинг состояния пациентов в больницах, рекомендации товаров в онлайн-магазине в момент просмотра.
Создание «единого источника истины»
Распределенная система может выступать в роли центрального и надежного хранилища данных, к которому могут подключаться множество других систем. Все системы получают данные из одного места, что гарантирует их согласованность.
Связь микросервисов
В современных приложениях, построенных на микросервисах, Kafka подходит для асинхронного обмена сообщениями между сервисами. Сервисы не связываются друг с другом напрямую, а общаются через платформу. Это повышает отказоустойчивость и масштабируемость.
Сбор и интеграция данных
Apache Kafka часто используют для передачи данных из одних систем хранения или обработки в другие. Она заменяет собой хрупкие и прямые соединения между системами. Помимо данных, платформа Apache Kafka также собирает большие объемы метрик и мониторит их.
Как работает Apache Kafka
Выше мы сравнивали Apache Kafka с привычными нам мессенджерами, где одни пользователи создают сообщения, а другие — их получают. Пойдем дальше. В этой цепочке Kafka создателя называют — producer или «издатель», а получателя — consumer или «подписчик».
Чтобы продюсер и консьюмер могли коммуницировать между собой, нужны определенные каналы — их называют «темы». Это похоже на канал в Telegram: автор канала отправляет сообщение в свой чат (темы), а подписчикам этого канала приходят уведомления о новых сообщениях. Эти «письма» получают все пользователи одного чата.
Но и это не все: внутри каждой темы есть разделы, которые создают специально для разных подписчиков. Так, например, сообщение может быть отправлено персонально или в «общий чат» с доступом для всех пользователей. Сообщения не приходят рандомно, они поступают по очереди. Apache Kafka способна анализировать миллионы таких «писем» ежесекундно.
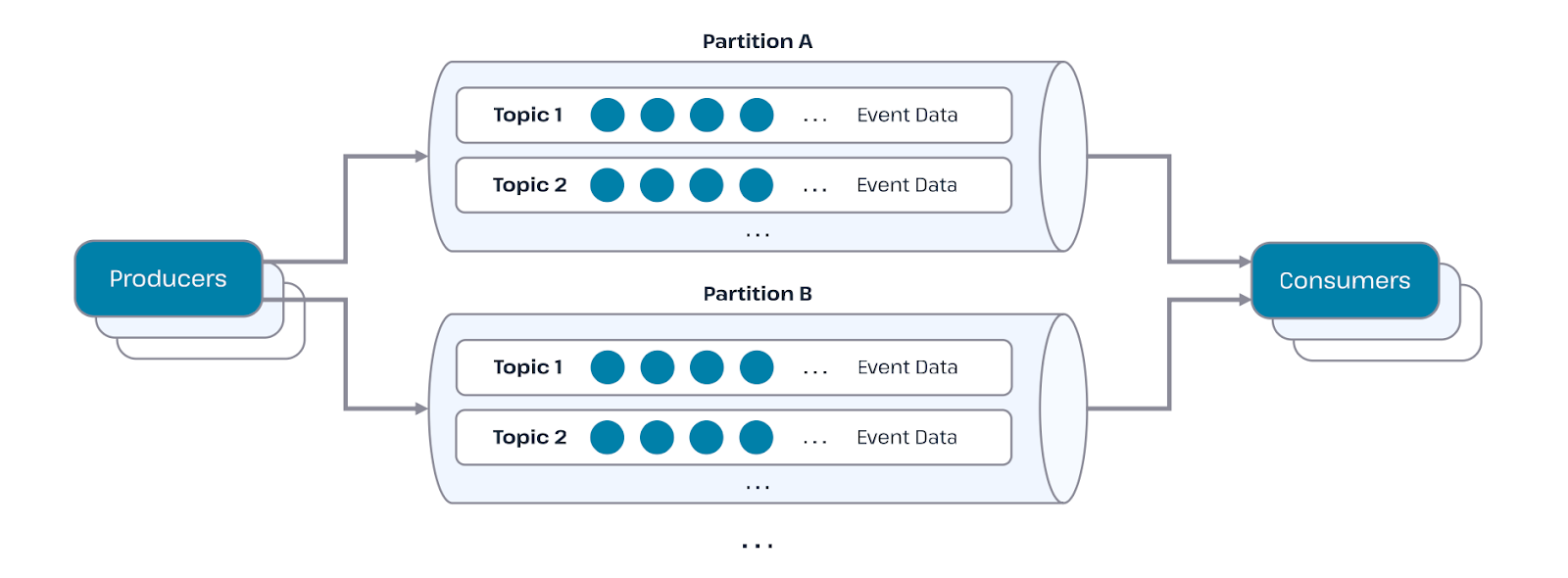
Система работает с массивами данных — может возникнуть риск, что сообщение затеряется. Поэтому в Apache Kafka предусмотрено строгое хранение сообщений — в журнале коммитов — где информация располагается в определенной последовательности. Ее нельзя корректировать или удалять, можно только добавлять.
Если тема становится слишком большой, то в нее добавляют секции, в которых сообщения сгруппированы по определенным критериям. Так потребителю будет проще будет найти то, что нужно, не перебирая весь топик.
Применение Apache Kafka
Теперь поговорим о коммерческом использовании Apache Kafka. Платформа нужна в самых разных отраслях — от ретейла и заводов до банков и медицинских учреждений. В общем, везде, где необходима real-time обработка данных.
Финансы и FinTech: банки и платежные системы применяют Kafka для мгновенного обнаружения мошеннических операций, отслеживания котировок на биржах и обработки транзакций здесь и сейчас.
Ретейл и e-commerce: крупные онлайн-магазины используют платформу, чтобы отслеживать поведение пользователей, формировать персональные рекомендации «на лету» и управлять запасами, синхронизируя данные между сайтом и складами.
Транспорт и логистика: такие сервисы, как Uber и Gett, используют Kafka для обработки данных о поездках, отслеживания местоположения автомобилей и динамического ценообразования.
Телекоммуникации: операторы связи обрабатывают с помощью Kafka миллиарды событий о качестве сетевого покрытия, звонках и использовании трафика для мониторинга и биллинга.
Здравоохранение: в медицинских учреждениях Kafka помогает в режиме реального времени собирать данные с датчиков мониторинга за пациентами, обеспечивая быстрое реагирование на критические изменения их состояния.
Интернет вещей (IoT): платформа — отличный «приемный пункт» для огромных потоков данных с миллионов умных устройств: от датчиков на производстве до приборов в «умном доме».
Преимущества Apache Kafka
Распределенная система завоевала популярность благодаря своим преимуществам:
Высокая отказоустойчивость и надежность
В Kafka каждое сообщение реплицируется (копируется) на несколько серверов (брокеров). Это означает, что при выходе из строя одного или даже нескольких узлов данные не будут потеряны, а система продолжит работу. Надежность же доставки обеспечивается моделью «точная однократная доставка», которая гарантирует, что сообщение будет обработано ровно один раз, что критически важно для финансовых операций или систем учета.
Горизонтальная масштабируемость
Систему можно легко масштабировать «на лету», просто добавляя новые серверы в кластер, без необходимости остановки работы. Это позволяет безболезненно справляться с резкими всплесками нагрузки, например, во время распродаж в «Черную пятницу». Благодаря распределенной архитектуре Kafka способна обрабатывать миллионы сообщений в секунду.
Высокая производительность
Kafka достигает высокой пропускной способности и низкой задержки за счет независимой организации процессов отправки и чтения сообщений. Тысячи приложений могут одновременно производить и потреблять данные параллельно, не мешая друг другу.
Долговременное хранение данных
В отличие от многих систем обмена сообщениями, Kafka не удаляет сообщения после их доставки. Данные сохраняются в течение заданного времени, что позволяет повторно обрабатывать информацию, анализировать ее позже или восстанавливать состояние системы на определенный момент.
Гибкость и универсальность экосистемы
У этой распределенной системы открытый исходный код. Благодаря этому у Kafka есть активное сообщество, большое количество документации и сторонние расширения. Она легко интегрируется с другими популярными системами, такими как Apache Spark, Flink и базами данных, через встроенный фреймворк Kafka Connect, и поддерживает множество протоколов.
Простота использования для разработчиков
Kafka предоставляет удобные API и готовые библиотеки для самых популярных языков программирования, что упрощает ее интеграцию в любую IT-инфраструктуру.
Сочетание этих преимуществ — надежности, масштабируемости, производительности и открытости — делает Apache Kafka не просто брокером сообщений, а полноценной платформой для построения центральной системы данных современного предприятия.
Руководство для начинающих
Работа с Kafka может показаться сложной, но ее базовые концепции достаточно просты для понимания. Давайте разберем основы Apache Kafka, чтобы понять, с чего начать. Вариант ниже подходит для Apache Kafka с ZooKeeper.

Установка и настройка
Шаг 1. Загрузите архив:
wget
https://archive.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
tar -xzf kafka_2.13-2.7.0.tgz
cd kafka_2.13-2.7.0
Шаг 2. В ZooKeeper найдите папку /bin, в которой есть скрипты для брокера и т. д. Затем запустите скрипт zookeeper-server-start.sh и передайте ему конфигурационный файл zookeeper.properties из папки ../config. В этом файле есть набор базовых переменных — благодаря этому можно быстро в тестовом режиме поднять ноду Kafka и ZooKeeper.
Шаг 3. Запустите брокер Kafka. Для этого в папке /bin введите скрипт kafka-server-start.sh и передайте ему конфигурационный файл server.properties из папки ../config. Здесь есть набор конфигураций для быстрого запуска брокера.
./bin/kafka-server-start.sh config/server.properties
Основные команды и рабочие процессы
Создание топика (topic)
Чтобы создать темы на сервере Kafka, воспользуйтесь утилитой командной строки kafka-topics.sh. Откройте новый терминал и введите пример ниже.
Синтаксис
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic topic-name
Пример: bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-Kafka
Готово! Вы создали топик Hello-Kafka — с одним разделом и одним фактором реплики. После создания топика в окне терминала брокера Kafka вы увидите уведомление, что операция успешно завершена.
Если же вам нужно получить список топиков на сервере Kafka, введите команду:
bin/kafka-topics.sh --list --zookeeper localhost:2181
Запуск продюсера (producer) для отправки сообщений
Здесь для клиента командной строки понадобится два параметра:
Broker-list — список брокеров, которым мы хотим отправлять сообщения.
Файл Config/server.properties — с идентификатором порта брокера. Так как мы знаем, что наш брокер слушает порт 9092, мы можем указать его напрямую.
Синтаксис
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-name
Запуск консьюмера (consumer) для получения сообщений
Как и с продюсером, свойства потребителя задаем в файле config/consumer.properties. Введите в новом терминале следующий синтаксис:
Синтаксис
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name
--from-beginning
Пример
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka
--from-beginning
Советы и рекомендации
Начните с локального развертывания. Не пытайтесь сразу настроить кластер в продакшене.
Поймите ключевые концепции. Прежде чем писать код, убедитесь, что вы понимаете, что такое топик, партиция, репликация, продюсер и консьюмер. Это основа.
Используйте Kafkacat или UI-инструменты. Для визуализации данных в топиках удобно использовать инструменты вроде Kafdrop или Kafka Tool. Они показывают список топиков, сообщения в очереди и смещения.
Правильно выбирайте количество партиций. Их количество можно увеличить, но нельзя уменьшить. Начинайте с малого (например, 1–3) для тестовых топиков.
Изучайте официальную документацию. Confluent и Apache Software Foundation публикуют отличные руководства и блоги с лучшими практиками.
Если вы хотите глубже погрузиться в программирование, рекомендуем присмотреться к курсам онлайн-школы ProductStar — здесь можно в короткие сроки освоить новую профессию и изучить Python, Java и многое другое. Подробности можно найти здесь.







