




Компании собирают огромные массивы данных: клики пользователей, логи сервисов, метрики приложений, транзакции. Источников все больше, а вот пользы от них — не всегда. Пока данные лежат в разных системах и форматах, они практически бесполезны.
Чтобы превратить сырой поток информации в понятную основу для отчетов и управленческих решений, используют ETL. Разберем, как работает этот подход и почему без него сложно представить современную аналитику.
Что такое ETL
ETL — это подход к работе с данными, который помогает собрать информацию из разных источников, привести ее в порядок и сложить в одно хранилище. Аббревиатура расшифровывается как “Extract, Transform, Load” — «Извлечь, Преобразовать, Загрузить».
Данные почти всегда разнородные. Например, у ретейлера офлайн-продажи хранятся в одной системе, онлайн-заказы — в другой, а маркетинг — в третьей. В этом контексте ETL-процесс решает, как объединять данные из разных источников. В итоге бизнес получает единую картину — для отчетов, прогнозов и автоматизации решений.
Где применяется ETL
ETL нужен везде, где данные приходят из разных источников и должны работать как единое целое. Это не узкая технология для айтишников, а базовый инструмент для бизнеса, аналитики и современных цифровых продуктов. Ниже — примеры применения ETL.
Хранилища и базы данных
ETL — основа любого data warehouse. Он используется при миграциях между системами и при постоянной загрузке данных из CRM, ERP, сайтов, касс, мобильных приложений. Задача ETL — поддерживать единые форматы и логику, чтобы данные не превращались в хаос по мере роста компании.
Аналитика и BI
В бизнес-, маркетинговой и продуктовой аналитике ETL незаменим. Он собирает показатели из разных каналов, очищает их и формирует единую картину для дашбордов, отчетов и прогнозов. Благодаря ETL аналитика опирается не на разрозненные цифры, а на согласованные и проверенные данные.
Big Data
В проектах с большими объемами информации данные постоянно перемещаются между системами хранения и обработки. ETL помогает масштабируемо загружать, фильтровать и подготавливать эти потоки, чтобы их можно было анализировать и использовать дальше — без ручной рутины.
Машинное обучение и AI
Для обучения моделей нужны качественные датасеты. ETL используется, чтобы собрать данные из разных источников, очистить их, привести к нужной структуре и загрузить в хранилище или напрямую в пайплайн обучения. Без этого ML-модели просто не будут давать адекватных результатов.
IoT и умные устройства
В системах интернета вещей данные поступают непрерывно — с датчиков, устройств, контроллеров. ETL позволяет агрегировать эти потоки, нормализовать показатели и сохранять историю для анализа, автоматизации и предиктивных сценариев.
Облака и миграции
При переезде в облако ETL используют для первичного переноса данных и для регулярной синхронизации новых поступлений. Он помогает безопасно и последовательно объединять данные из локальных систем, SaaS-сервисов и облачных платформ.
Как работает ETL-процесс
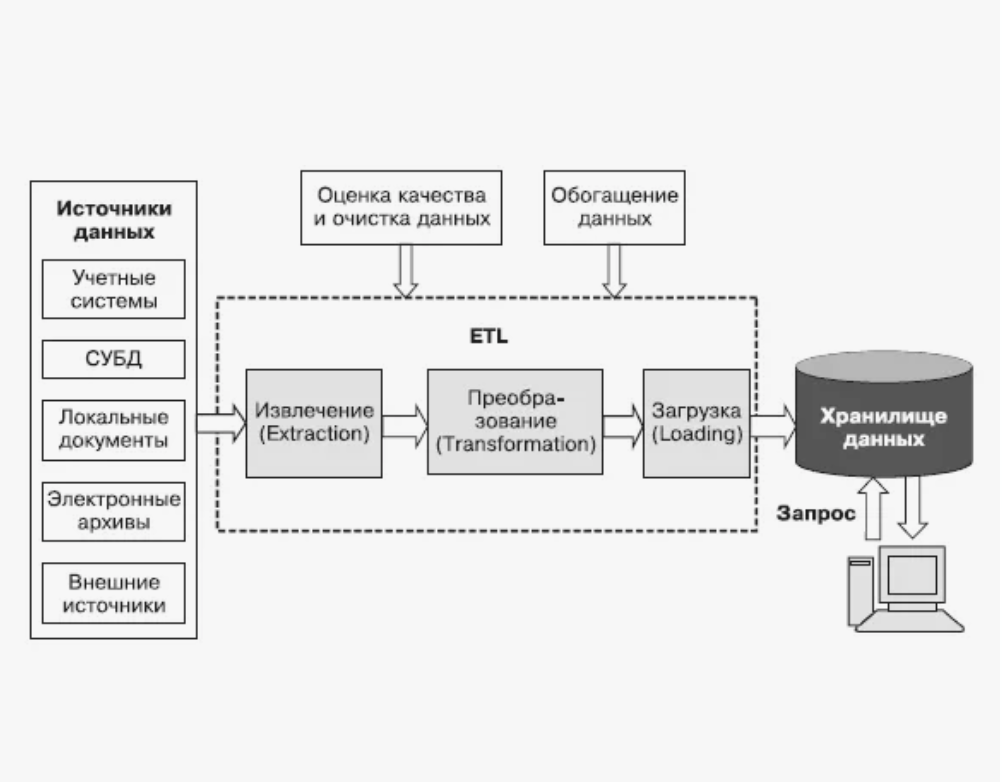
Extract — извлечение
На старте ETL забирает информацию из баз данных, сервисов, файлов, приложений. Информация копируется во временную зону, где система может проверить ее целостность: хватает ли полей, корректны ли значения, можно ли перенести данные без потерь. Это позволяет отсеять ошибки еще до загрузки в хранилище.
Transform — преобразование
Дальше информация обрабатывается. Здесь определяется, как агрегировать данные для суммарных показателей и как обрабатывать дубликаты. ETL меняет форматы, кодировки и структуру, очищает лишнее, объединяет справочники и рассчитывает нужные показатели. Это позволяет сделать данные единообразными и совместимыми с требованиями целевой системы.
Load — загрузка
На финальном этапе подготовленные данные отправляются в хранилище и раскладываются по нужным таблицам. Вместе с ними могут передаваться метаданные — информация о структуре, типах полей и связях. После этого данные готовы к аналитике, отчетам и дальнейшему использованию.
Далее подробнее поговорим о каждом этапе ETL.
Извлечение данных
Есть три способа извлечения данных. Выбор зависит от того, умеет ли источник сообщать об изменениях и как часто данные обновляются.
Полное извлечение
Система каждый раз выгружает все данные целиком. Изменения не отслеживаются — новые и старые записи передаются вместе. Такой метод подходит для небольших таблиц или редких загрузок.
Инкрементное извлечение
ETL забирает только те записи, которые изменились с момента последней загрузки — например, за день, неделю или другой период. Источник может помечать обновления по дате, версии или специальному флагу. Инкремент снижает объем передаваемых данных и подходит для регулярных обновлений.
Уведомления об обновлениях
Источник сам сообщает о том, что данные изменились: через триггеры, события или API-уведомления. ETL запускается только при реальных обновлениях и извлекает нужные записи сразу. Такой подход минимизирует задержки и нагрузку, но требует поддержки со стороны системы-источника.
Преобразование данных
Преобразование — самый объемный этап ETL. Он состоит из пяти этапов.
Чистка данных. На этом шаге убирают ошибки и неточности: пустые значения заменяют на допустимые, исправляют некорректные записи, приводят справочники к единому виду. В результате данные становятся предсказуемыми и не ломают отчеты.
Дедупликация записей. ETL ищет и удаляет дубли — повторяющиеся клиенты, заказы или события. Это особенно важно, когда данные приходят из нескольких систем. Без дедупликации аналитика легко увеличивается и искажает реальные показатели.
Изменение форматов. Данные часто хранятся в разных форматах: даты, валюты, единицы измерения, кодировки. ETL приводит их к общему стандарту, чтобы значения можно было корректно сравнивать и агрегировать данных.
Агрегирование. Чтобы работать не с миллионами строк, а с осмысленными показателями, данные объединяют и суммируют. Например, считают выручку за период, средний чек или метрики по клиенту. Это снижает объем данных и ускоряет аналитику.
Объединение. ETL связывает информацию из разных источников: продажи — с клиентами, заказы — с товарами, расходы — с выручкой. Так, формируется целостная модель данных, на которой строятся отчеты и прогнозы.
Загрузка данных
Загрузка — финальный этап ETL. В зависимости от задач и объема данных используют несколько подходов. Ниже — рассмотрим три из них.
Полная загрузка
Все данные переносятся целиком, без учета изменений. Такой режим применяют при первом наполнении хранилища или при редких перезагрузках. Метод простой и надежный, но ресурсоемкий, поэтому подходит только для стартовых этапов или небольших наборов данных.
Инкрементная загрузка
Загружается только разница между источником и хранилищем — новые или измененные записи. ETL отслеживает момент последней загрузки и обновляет данные по расписанию. Этот вариант снижает нагрузку на системы и используется в большинстве рабочих сценариев.
Потоковая загрузка
Разновидность инкрементного подхода для данных, которые обновляются постоянно. Изменения передаются в хранилище почти в реальном времени через data-конвейеры или обработку событий. Такой формат нужен для онлайн-аналитики, мониторинга и быстрых бизнес-решений.
ETL vs ELT
ETL и ELT решают одну задачу — доставить данные в хранилище и подготовить их к аналитике. Главное отличие между подходами — в порядке действий.
ELT (Extract → Load → Transform). Здесь данные почти сразу попадают в хранилище в «сыром» виде, а преобразования выполняются уже внутри него. ELT хорошо сочетается с современными облачными платформами, которые умеют быстро обрабатывать большие объемы информации.
Этот подход чаще используют для Big Data, продуктовой аналитики и сценариев, где важна скорость и гибкость — например, в e-commerce, маркетинге или медиа.
ETL выбирают, когда важны контроль качества, сложная бизнес-логика и требования к безопасности. Такой подход часто используют в финансах, банках и медицине, где данные чувствительные и должны соответствовать регуляторным нормам.
На практике компании все чаще комбинируют оба метода, подстраиваясь под конкретные задачи и архитектуру данных.
Инструменты для ETL-процессов
Для построения ETL-пайплайнов используют как open-source-инструменты, так и корпоративные платформы. Выбор зависит от масштаба данных, инфраструктуры и требований к автоматизации.
Apache Airflow — это не классический ETL, а инструмент оркестрации. Его используют, чтобы управлять ETL-процессами: запускать задачи по расписанию, отслеживать зависимости и контролировать сбои. На практике команды решают, как настраивать Airflow для ETL, описывая зависимости, расписания и обработку ошибок в коде. Инструмент особенно популярен в data-командах и гибких аналитических проектах.
Apache NiFi — подходит для управления потоками данных между разными системами. У него визуальный интерфейс, где пайплайны собираются из блоков без кода. Инструмент хорошо справляется с потоковыми и событийными данными, масштабируется и позволяет детально отслеживать происхождение каждой записи.
Talend — универсальный ETL-инструмент с визуальным конструктором и большим набором готовых коннекторов. Его часто выбирают для классических задач интеграции данных, очистки и профилирования. Talend удобен для команд, которым важен быстрый старт без сложной разработки.
Informatica — корпоративный стандарт для работы с большими и критичными данными. Платформа ориентирована на сложные ETL-сценарии, управление качеством данных и метаданными. Ее используют крупные компании, где важны масштабируемость, безопасность и соответствие регуляторным требованиям.
AWS Glue — облачный ETL-сервис для тех, кто работает внутри экосистемы Amazon. Он автоматически определяет структуру данных, выполняет преобразования на базе Spark и не требует управления серверами. Подходит для data lake, ELT-подходов и масштабируемой аналитики в облаке.
В реальных проектах инструменты часто комбинируют: например, Airflow — для оркестрации, NiFi — для потоков и Glue или Talend — для трансформаций. Такой стек позволяет гибко подстроить ETL под задачи бизнеса.
Проблемы и ограничения ETL
ETL — мощный, но не универсальный инструмент. При его внедрении и эксплуатации важно учитывать ряд ограничений, которые напрямую влияют на сроки, бюджет и качество аналитики.
Трудоемкость и сложность внедрения
ETL-процессы редко бывают простыми. Компании работают с десятками источников, разными форматами и уровнями структурированности данных. Под каждую систему нужны свои правила извлечения и преобразования, а сложная бизнес-логика требует времени на разработку и тестирование.
Требования к инфраструктуре
По мере роста объемов данных нагрузка на ETL увеличивается. Локальных серверов и пакетных загрузок со временем может стать недостаточно. Без продуманной архитектуры и масштабируемой инфраструктуры ETL начинает тормозить аналитику и мешать росту бизнеса.
При увеличении нагрузки важно понимать, как оптимизировать ETL-процессы, а также — как тестировать ETL pipelines, чтобы изменения не ломали существующую аналитику.
Риски качества данных
ETL напрямую зависит от входных данных. Если источники содержат ошибки, пропуски или несогласованные значения, проблемы «переезжают» в хранилище. В итоге отчеты выглядят корректно, но отражают искаженную картину. Поэтому важно заранее продумать, как контролировать ошибки при загрузке, чтобы минимизировать риски.
Ограничения по скорости и актуальности
Классический ETL чаще ориентирован на пакетную обработку. Это усложняет работу с данными в реальном времени и требует дополнительных решений для потоковой загрузки и быстрого обновления показателей.
Безопасность и соответствие требованиям
При обработке чувствительных данных ETL должен учитывать требования к защите и хранению информации. Контроль доступа, шифрование и аудит усложняют архитектуру и повышают требования к инструментам и команде.
Примеры использования
Загрузка данных в хранилище. Банк ВТБ использовал ETL-подход для создания централизованного хранилища данных. Решение позволило объединить и синхронизировать сведения из внутренних информационных систем, обеспечить миграцию данных в новые приложения и наладить обмен информацией с внешними контрагентами.
В результате была сформирована единая аналитическая среда на основе масштабируемого MPP-кластера, соответствующая строгим требованиям по доступности данных и управлению ими.
Подготовка отчетности и аналитики. Онлайн-кинотеатр ivi.ru применил ETL для переноса данных из реляционных СУБД и NoSQL-хранилищ в аналитические системы Vertica и Yandex ClickHouse. Это позволило стандартизировать процессы загрузки и трансформации данных, внедрить централизованный контроль выполнения и значительно ускорить формирование отчетов.
В результате компания снизила затраты на сопровождение инфраструктуры и получила более быстрый доступ к данным для финансовой отчетности и управленческого анализа.
Пример миграции данных через ETL в облако. В кейсе, описанном на «Хабре», платформа Modus BI и Modus ETL использовались для переноса аналитических данных из PostgreSQL в ClickHouse. Проблема заключалась в медленном обновлении дашбордов. После миграции и перестройки ETL-пайплайнов производительность аналитических запросов заметно выросла, а обновление данных стало стабильным и быстрым.
Заключение
ETL дает бизнесу единый источник правды, исторический контекст и автоматизацию рутинных операций. Он связывает разрозненные источники, превращает «сырые» выгрузки в понятную структуру и делает аналитику надежной. Без ETL сложно масштабировать хранилища, автоматизировать отчетность и принимать решения на основе данных, а не интуиции.
В итоге решения принимаются быстрее, аналитика становится точнее, а команды тратят время на развитие продукта, а не на ручную обработку данных.
Если вам интересны разные подходы к работе с данными, приходите учиться в онлайн-школу ProductStar. Здесь вас ждет 17 профильных программ обучения длительностью от 1 месяца до года. Подходит для студентов с разным уровнем подготовки.
FAQ
Как проверять качество данных?
Контроль качества закладывают на этапах извлечения и преобразования. Проверяют заполненность полей, типы данных, диапазоны значений, уникальность ключей и связи между таблицами. В ETL добавляют автоматические валидаторы, логирование и алерты — так ошибки ловятся сразу, а не всплывают в отчетах.
Как извлекать данные правильно?
Начните с анализа источника: частота обновлений, способы отслеживания изменений и лимиты по нагрузке. Для регулярных задач используйте инкрементальное извлечение или события. Полную выгрузку имеет смысл делать только при первичной загрузке или для небольших таблиц.
Как преобразовывать данные в ETL?
Трансформации строятся по бизнес-логике. Данные очищают, дедуплицируют, приводят форматы к единому стандарту и считают нужные метрики. Правила преобразований важно документировать — это делает расчеты прозрачными и воспроизводимыми.
Как делать инкрементальную загрузку?
Инкремент работает с «дельтой» — записями, изменившимися с прошлого запуска. Здесь используют временные метки, версии строк или флаги изменений. ETL хранит состояние последней загрузки и обновляет только актуальные данные, снижая нагрузку на источники.
Как делать потоковую загрузку?
Потоковая загрузка нужна, когда данные требуются почти в реальном времени. В этом случае события обрабатываются по мере поступления с помощью брокеров сообщений и стриминговых платформ. Важно учитывать порядок событий, обработку задержек и гарантии доставки, чтобы данные оставались корректными и согласованными.







